엑셀 웹크롤링을 위해 필요한 파일을 다운로드하였다면, 이제 직접 크롤링을 해볼 것입니다. 이글에서는 웹에서 다양한 요소를 선택하는 방법을 알아볼 것입니다. 웹의 구성요소에 따라 사용방법이 다를 수 있으니, 모두 익혀놓거나, 하나만 잘 익혀두고 나머지는 나중에 배워도 좋습니다.

목차
웹 크롤링 기본과 WebDriver 이해
웹 크롤링은 웹사이트에서 자동으로 데이터를 추출하는 기술입니다. 엑셀 VBA를 활용하면 별도의 프로그래밍 언어 없이 구현할 수 있습니다. 이를 위해 WebDriver(ChromeDriver)라는 객체를 사용하여 웹 브라우저를 제어합니다.
WebDriver 설정 기본
VBA에서 WebDriver를 사용하기 위해서는 먼저 참조 설정이 필요합니다. VBA 편집기에서 '도구 > 참조'를 선택한 후 'Selenium Type Library'를 찾아 체크하면 됩니다. 일반적으로 Selenium Basic이나 관련 라이브러리를 먼저 설치해야 합니다.(이전글 참조, 엑셀로 웹크롤링하기 셀레늄 설치하기 )
웹크롤링이 이루어지는 과정
웹사이트는 html이라는 언어로 이루어져 있습니다. 어떤 웹사이트에 들어가면, 큰 문자, 작은 문자, 제목 이런 것들이 있지요. 이것의 뒤에는 html이라는 언어가 숨어있습니다. 저희는 이 html코드를 찾아낸 후에, 그 코드를 이용해서 vba, 셀레늄을 통해 그 코드의 정보를 가져오기도 하고, 저희가 그 코드에 요청을 하기도 합니다.
VBA로 네이버, 구글 검색해 보기(맛보기)
1. 네이버 검색 자동화하기
Sub naverStart()
'03/06/19 네이버의 ID 필드를 위해 사용하고 있음
Dim bot As New WebDriver
bot.Start "chrome", "https://www.naver.com"
bot.Get "/"
'네이버 검색창에 '맛있는 치킨' 입력하기
bot.FindElementById("query").SendKeys "맛있는 치킨"
'엔터 키
bot.SendKeys bot.Keys.Enter
End Sub이 코드는 네이버 웹사이트에 접속하여 자동으로 검색을 수행하는 과정을 보여줍니다. WebDriver 객체를 생성하고 Chrome 브라우저를 실행한 다음, 네이버 홈페이지로 이동합니다. 그 후 검색창(ID가 "query"인 요소)을 찾아 "맛있는 치킨"이라는 검색어를 입력하고 Enter 키를 눌러 검색을 실행합니다.
2. 구글 검색 자동화하기
Sub googStart()
'03/06/19 야후의 ID 필드를 위해 사용하고 있지만, 여전히 name="q"를 사용하여 NAME으로 찾을 수 있음
Dim bot As New WebDriver
bot.Start "chrome", "https://www.google.com"
bot.Get "/"
'구글 검색창에 class을 사용하여 'hello world' 입력하기
bot.FindElementByClass("gLFyf").SendKeys "맛있는 치킨"
'구글 검색창에 NAME을 사용하여 'hello world' 입력하기
bot.FindElementByName("q").SendKeys " 만드는법"다양한 요소 선택하는 방법 (태그, 클래스, ID 등)
웹사이트 내에서 특정요소를 선택하는 방법은 여러 가지가 있는데, 여기서는 아래 5 가지를 소개합니다. 간단하게 말하자면, 웹페이지 내의 특정 요소에는 태그, 클래스등의 꼬리표가 달려있는데 이것을 찾는 방법이 아래 5가지와 같다고 생각하시면 됩니다.
- FindElementByTag
- FindElementByClass
- FindElementById
- FindElementByLinkText
- FindElementByCss
1. 태그로 요소 찾기(FindElementByTag)
Sub byTag()
Dim bot As New WebDriver
myUrl = "https://eictionary.tistory.com/entry/%EC%97%91%EC%85%80%EB%A1%9C-%EC%9B%B9%ED%81%AC%EB%A1%A4%EB%A7%81%ED%95%98%EA%B8%B0-%EC%85%80%EB%A0%88%EB%8A%84-%EC%84%A4%EC%B9%98%ED%95%98%EA%B8%B0"
bot.Start "chrome", myUrl
bot.Get myUrl
'find first H1 tag
headerText = bot.FindElementByTag("h1").Text
'find first paragraph
firstParagraph = bot.FindElementByTag("p").Text
'find first label
firstLabel = bot.FindElementByTag("label").Text
MsgBox ("h1태그는: " & headerText & vbCr & vbCr & "첫번째문단은: " & firstParagraph & vbCr & vbCr & "첫번째 레이블은: " & firstLabel)
End Sub
2. 클래스로 요소의 텍스트 가져오기(FindElementByClass)
Sub byClass()
Dim bot As New WebDriver
myUrl = "https://eictionary.tistory.com/entry/%EC%97%91%EC%85%80%EB%A1%9C-%EC%9B%B9%ED%81%AC%EB%A1%A4%EB%A7%81%ED%95%98%EA%B8%B0-%EC%85%80%EB%A0%88%EB%8A%84-%EC%84%A4%EC%B9%98%ED%95%98%EA%B8%B0"
bot.Start "chrome", myUrl
bot.Get myUrl
myVar = bot.FindElementByClass("book-toc").Text
MsgBox myVar
End Sub3. 이름(name) 요소의 텍스트 가져오기(FindElementByName)
Sub name찾기()
Dim bot As New WebDriver
myUrl = "https://eictionary.tistory.com/entry/%EC%97%91%EC%85%80%EB%A1%9C-%EC%9B%B9%ED%81%AC%EB%A1%A4%EB%A7%81%ED%95%98%EA%B8%B0-%EC%85%80%EB%A0%88%EB%8A%84-%EC%84%A4%EC%B9%98%ED%95%98%EA%B8%B0"
bot.Start "chrome", myUrl
bot.Get myUrl
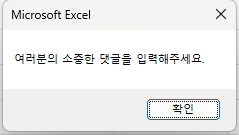
myvar = bot.FindElementByName("comment").Attribute("placeholder")
MsgBox myvar
End Sub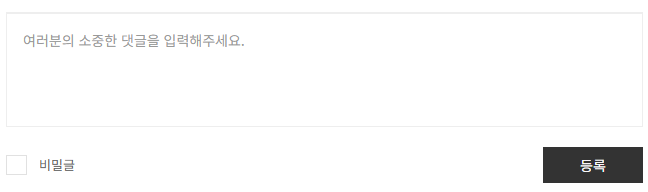

4. 링크텍스트(하이퍼링크, a태그) 요소 가져오기(FindElementByLinkText)
Sub byLinkText()
Dim bot As New WebDriver
myUrl = "https://eictionary.tistory.com/entry/%EC%97%91%EC%85%80%EB%A1%9C-%EC%9B%B9%ED%81%AC%EB%A1%A4%EB%A7%81%ED%95%98%EA%B8%B0-%EC%85%80%EB%A0%88%EB%8A%84-%EC%84%A4%EC%B9%98%ED%95%98%EA%B8%B0"
bot.Start "chrome", myUrl
bot.Get myUrl
'BY EXACT LINK TEXT
bot.FindElementByLinkText("웹크롤링").Click
End Sub
웹페이지 내에서 특정링크로 이동하는 텍스트가 있다면, 그 텍스트를 찾아주는 명령어입니다. 그 텍스트는 정확하게 적혀야 합니다. 다음 예시를 보시죠.
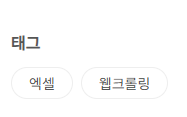
위에서 보이는 사진에는 두 가지 태그가 있습니다. "엑셀", "웹크롤링" 이 중에서 "웹크롤링"이라는 태그를 찾아서 클릭해 보겠습니다. bot.FindElementByLinkText("웹크롤링").Click 이 명령어와 같이, "웹크롤링"이라는 텍스트가 링크텍스트를 찾아서, 클릭하는 명령어입니다. 정확성은 굉장히 낮기 때문에, 규칙성이 있을 때 사용하는 것이 좋겠습니다.
※참고 bot.FindElementByPartialLinkText("텍스트").Click
링크가 있는 텍스트중 일부를 찾아서 클릭하는 명령입니다. 정확성은 더 낮지만, 규칙성이 있는 웹사이트에서 사용할 수 있습니다. 부분 링크 텍스트 검색은 링크의 전체 텍스트가 아닌 일부만 알고 있을 때 유용합니다. 이 코드는 "텍스트"라는 단어를 포함하는 링크를 찾아 클릭합니다. 이 방식은 웹사이트 디자인이 변경되거나 다국어 지원이 필요한 경우에도 유연하게 대응할 수 있습니다.
5.CSS로 요소 가져오기.
Sub byCSS()
Dim bot As New WebDriver
bot.Start "chrome", "https://en.wikipedia.org/wiki/Special:Random"
bot.Get "/"
'h1텍스트와, h2텍스트 찾기
'H1Text = bot.FindElementByCss("body > div.mw-page-container:nth-child(3) > div.mw-page-container-inner > div.mw-content-container:nth-child(3) > main#content.mw-body > header.mw-body-header.vector-page-titlebar:nth-child(1) > h1#firstHeading.firstHeading.mw-first-heading:nth-child(2) > span.mw-page-title-main").Text
H1Text = bot.FindElementByCss("h1#firstHeading").Text
H2Text = bot.FindElementByCss("div.mw-heading.mw-heading2 > h2").Text
MsgBox (H1Text)
MsgBox (H2Text)
End Sub
CSS 선택자는 복잡한 요소 계층 구조를 탐색하는 데 매우 강력한 도구입니다. 이 코드는 위키피디아의 랜덤 페이지에서 h1태그와, h2태그를 찾는 코드입니다. 어떻게 보면 그냥 태그 찾기로 생각하실수 있으나, 일반적인 태그로 찾는 것보다 더 복잡한 홈페이지에서 요소를 찾을 수 있습니다. 간단히 설명하자면 아래와 같습니다.
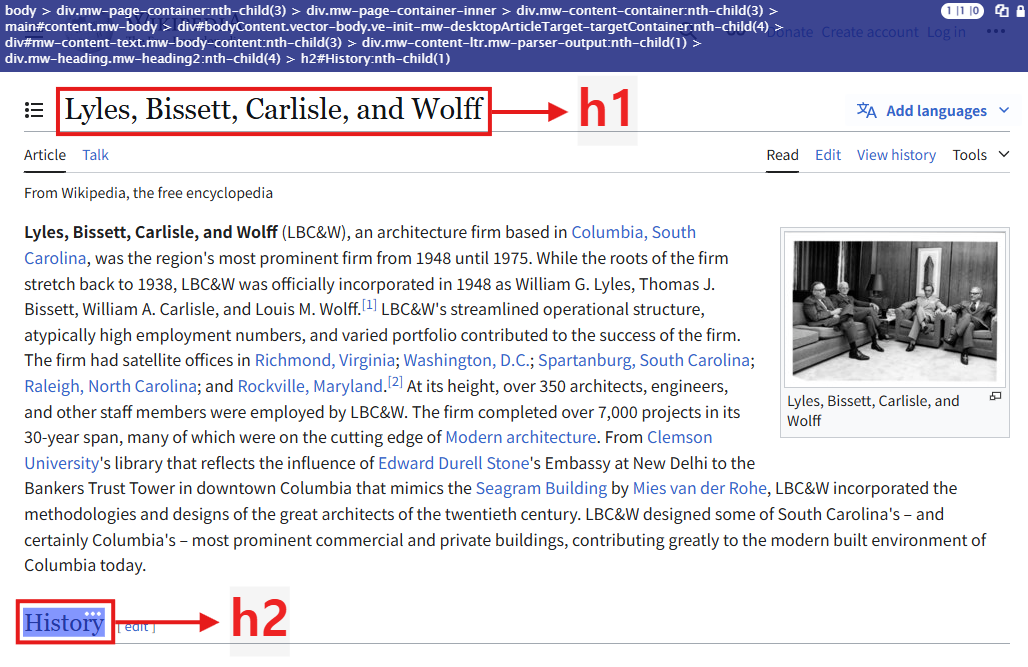
*h1의 코드
body > div.mw-page-container:nth-child(3) > div.mw-page-container-inner > div.mw-content-container:nth-child(3) > main#content.mw-body > header.mw-body-header.vector-page-titlebar:nth-child(1) > h1#firstHeading.firstHeading.mw-first-heading:nth-child(2) > span.mw-page-title-main
*첫 번째 h2의 코드
body > div.mw-page-container:nth-child(3) > div.mw-page-container-inner > div.mw-content-container:nth-child(3) > main#content.mw-body > div#bodyContent.vector-body.ve-init-mw-desktopArticleTarget-targetContainer:nth-child(4) > div#mw-content-text.mw-body-content:nth-child(3) > div.mw-content-ltr.mw-parser-output:nth-child(1) > div.mw-heading.mw-heading2:nth-child(4) > h2#History:nth-child(1)
태그로 찾는 것은 단순하게 h1, h2이렇게 찾는것에 불과한데요. 이러면 단순한 페이지에서는 잘 구동할수있으나, 조금더 복잡한 페이지에서는 원한는 요소를 찾기 어렵습니다. 거기에반해 css요소로 찾는것은 복잡한 구조도 찾아낼 수 있습니다.
더 깊은 내용은 후에 다른 글에서 적어보겠습니다.
이 글에서는 웹페이지에서 요소들을 선택하는 다양한 방법을 알아보았습니다.
이를 더 깊이 알려고 해도 좋지만, 처음부터 깊게 생각하면 나중에 배우기가 더 힘들어지므로, 일단은 얕고 빠르게 기능들을 익히고 난 후에 실제 프로젝트를 해보면서 자신에게 필요한 걸 공부하시길 바랍니다.
'엑셀' 카테고리의 다른 글
| 엑셀 날짜가 텍스트로 인식될때 조치법, 1분 안에 (0) | 2025.04.07 |
|---|---|
| 엑셀로 웹크롤링하기 셀레늄 설치하기 (0) | 2025.03.26 |
| 4조 2교대 엑셀 vba 시트 연도별 파일 다운로드 (0) | 2025.03.23 |
| VBA 워크 시트 참조 정석 3가지, 90%는 모름 (0) | 2024.11.18 |
| 엑셀 Vba 조건문 사용하는 3가지 방법 (0) | 2024.11.18 |




댓글